炬芯科技周正宇:Actions Intelligence 端側AI音頻芯未來(lái)

ChatGPT激發(fā)了人們的好奇心也打開(kāi)了人們的想象力,伴隨著(zhù)生成式AI(Generative AI)以史無(wú)前例的速度被廣泛采用,AI算力的需求激增。與傳統計算發(fā)展路徑類(lèi)似,想讓AI普及且發(fā)掘出AI的全部潛力,AI計算必須合理的分配在云端服務(wù)器和端側裝置(如PC,手機,汽車(chē), IoT裝置),而不是讓云端承載所有的AI負荷。這種云端和端側AI協(xié)同作戰的架構被稱(chēng)為混合AI(Hybrid AI),將提供更強大,更有效和更優(yōu)化的AI。換句話(huà)說(shuō),要讓AI真正觸手可及,深入日常生活中的各種場(chǎng)景,離不開(kāi)端側AI的落地。
端側AI將機器學(xué)習帶入每一個(gè)IoT設備,減少對云端算力的依賴(lài),可在無(wú)網(wǎng)絡(luò )連接或者網(wǎng)絡(luò )擁擠的情況下,提供低延遲AI體驗、還具備低功耗,高數據隱私性和個(gè)性化等顯著(zhù)優(yōu)勢。AIoT的一個(gè)最重要載體是電池驅動(dòng)的超低功耗小型IoT設備,其數量龐大且應用豐富,在新一代AI的浪潮中,端側AI是實(shí)現人工智能無(wú)處不在的關(guān)鍵,而為電池驅動(dòng)的低功耗IoT裝置賦能AI又是讓端側AI變?yōu)楝F實(shí)的關(guān)鍵。
2024年11月5日,炬芯科技股份有限公司董事長(cháng)兼CEO周正宇博士受邀出席Aspencore2024全球CEO峰會(huì ),結合AI時(shí)代熱潮及端側AI所帶來(lái)的新一代AI趨勢,分享炬芯科技在低功耗端側AI音頻的創(chuàng )新技術(shù)及重磅產(chǎn)品,發(fā)表主題演講:《Actions Intelligence: 端側AI音頻芯未來(lái)》。

周正宇博士表示:在從端側AI到生成式AI的廣泛應用中,不同的AI應用對算力資源需求差異顯著(zhù),而許多端側AI應用是專(zhuān)項應用, 并不需要大模型和大算力。 尤其是以語(yǔ)音交互,音頻處理,預測性維護,健康監測等為代表的AIoT領(lǐng)域。
在便攜式產(chǎn)品和可穿戴產(chǎn)品等電池驅動(dòng)的IoT設備中,炬芯科技致力于在毫瓦級功耗下實(shí)現TOPS級別的AI算力,以滿(mǎn)足IoT設備對低功耗、高能效的需求。以穿戴產(chǎn)品(耳機和手表)為例, 平均功耗在10mW-30mW之間, 存儲空間在10MB以下,這框定了低功耗端側AI,尤其是可穿戴設備的資源預算。
周正宇博士指出”Actions Intelligence”是針對電池驅動(dòng)的端側AI落地提出的戰略,將聚焦于模型規模在一千萬(wàn)參數(10M)以下的電池驅動(dòng)的低功耗音頻端側AI應用,致力于為低功耗AIoT裝置打造在10mW-100mW之間的功耗下提供0.1-1TOPS的通用AI算力。也就是說(shuō)”Actions Intelligence“將挑戰目標10TOPS/W-100TOPS/W的AI算力能效比。根據ABI Research預測,端側AI市場(chǎng)正在快速增長(cháng),預計到2028年,基于中小型模型的端側AI設備將達到40億臺,年復合增長(cháng)率為32%。到2030年,預計75%的這類(lèi)AIoT設備將采用高能效比的專(zhuān)用硬件。
現有的通用CPU和DSP解決方案雖然有非常好的算法彈性,但是算力和能效遠遠達不成以上目標,依據ARM和Cadence的公開(kāi)資料,同樣使用28/22nm工藝,ARM A7 CPU 運行頻率1.2GHz時(shí)可獲取0.01TOPS的理論算力,需要耗電100mW,即理想情況下的能效比僅為0.1TOPS/W;HiFi4 DSP運行600MHz時(shí)可獲取0.01TOPS的理論算力,需要耗電40mW,即理想情況下的能效比0.25TOPS/W。即便專(zhuān)用神經(jīng)網(wǎng)路加速器(NPU)的IP ARM周易能效比大幅提升,但也僅為2TOPS/W。
以上傳統技術(shù)的能效比較差的本質(zhì)原因均源于傳統的馮?諾依曼計算結構。傳統的馮?諾伊曼計算系統采用存儲和運算分離的架構,存在“存儲墻”與“功耗墻”瓶頸,嚴重制約系統算力和能效的提升。
在馮?諾伊曼架構中,計算單元要先從內存中讀取數據,計算完成后,再存回內存。隨著(zhù)半導體產(chǎn)業(yè)的發(fā)展和需求的差異,處理器和存儲器二者之間走向了不同的工藝路線(xiàn)。由于工藝、封裝、需求的不同,存儲器數據訪(fǎng)問(wèn)速度跟不上處理器的數據處理速度,數據傳輸就像處在一個(gè)巨大的漏斗之中,不管處理器灌進(jìn)去多少,存儲器都只能“細水長(cháng)流”。兩者之間數據交換通路窄以及由此引發(fā)的高能耗兩大難題,在存儲與運算之間筑起了一道“存儲墻”。
此外,在傳統架構下,數據從內存單元傳輸到計算單元需要的功耗是計算本身的許多倍,因此真正用于計算的能耗和時(shí)間占比很低,數據在存儲器與處理器之間的頻繁遷移帶來(lái)嚴重的傳輸功耗問(wèn)題,稱(chēng)為“功耗墻”。
周正宇博士表示:弱化或消除”存儲墻”及”功耗墻”問(wèn)題的方法是采用存內計算Computing-in-Memory(CIM)結構。其核心思想是將部分或全部的計算移到存儲中,讓存儲單元具有計算能力,數據不需要單獨的運算部件來(lái)完成計算,而是在存儲單元中完成存儲和計算,消除了數據訪(fǎng)存延遲和功耗,是一種真正意義上的存儲與計算融合。同時(shí),由于計算完全依賴(lài)于存儲,因此可以開(kāi)發(fā)更細粒度的并行性,大幅提升性能尤其是能效比。
機器學(xué)習的算法基礎是大量的矩陣運算,適合分布式并行處理的運算,存內計算非常適用于人工智能應用。
要在存儲上做計算,存儲介質(zhì)的選擇是成本關(guān)鍵。單芯片為王,炬芯的目標是將低功耗端側AI的計算能力和其他SoC的模塊集成于一顆芯片中,于是使用特殊工藝的DDR RAM和Flash無(wú)法在考慮范圍內。而采用標準SoC適用的CMOS工藝中的SRAM和新興NVRAM(如RRAM或者M(jìn)RAM)進(jìn)入視野。SRAM工藝非常成熟,且可以伴隨著(zhù)先進(jìn)工藝升級同步升級,讀寫(xiě)速度快、能效比高,并可以無(wú)限多次讀寫(xiě)。唯一缺陷是存儲密度較低,但對于絕大多數端側AI的算力需求,該缺陷不會(huì )成為阻力。短期內,SRAM是在低功耗端側AI設備上打造高能效比的最佳技術(shù)路徑,且可以快速落地,沒(méi)有量產(chǎn)風(fēng)險。
長(cháng)期來(lái)看,新興NVRAM 如RRAM由于密度高于SRAM,讀功耗低,也可以集成入SoC,給存內計算架構提供了想象空間。但是RRAM工藝尚不成熟,大規模量產(chǎn)依然有一定風(fēng)險,制程最先進(jìn)只能到22nm,且存在寫(xiě)次數有限的致命傷(超過(guò)會(huì )永久性損壞)。故周正宇博士預期未來(lái)當RRAM技術(shù)成熟以后,SRAM 跟RRAM的混合技術(shù)有機會(huì )成為最佳技術(shù)路徑,需要經(jīng)常寫(xiě)的AI計算可以基于SRAM的CIM實(shí)現,不經(jīng)?;蛘哂邢薮螖祵?xiě)的AI計算由RRAM的CIM實(shí)現,基于這種混合技術(shù)有望實(shí)現更大算力和更高的能效比。
業(yè)界公開(kāi)的基于SRAM的CIM電路有兩種主流的實(shí)現方法,一是在SRAM盡量近的地方用數字電路實(shí)現計算功能, 由于計算單元并未真正進(jìn)入SRAM陣列,本質(zhì)上這只能算是近存技術(shù)。另一種思路是在SRAM介質(zhì)里面利用一些模擬器件的特性進(jìn)行模擬計算,這種技術(shù)路徑雖然實(shí)現了真實(shí)的CIM,但缺點(diǎn)也很明顯。一方面模擬計算的精度有損失,一致性和可量產(chǎn)性完全無(wú)法保證,同一顆芯片在不同的時(shí)間不同的環(huán)境下無(wú)法確保同樣的輸出結果。另一方面它又必須基于A(yíng)DC和DAC來(lái)完成基于模擬計算的CIM和其他數字模塊之間的信息交互, 整體數據流安排以及界面交互設計限制多,不容易提升運行效率。
炬芯科技創(chuàng )新性的采用了基于模數混合設計的電路實(shí)現CIM,在SRAM介質(zhì)內用客制化的模擬設計實(shí)現數字計算電路,既實(shí)現了真正的CIM,又保證了計算精度和量產(chǎn)一致性。
周正宇博士認為,炬芯科技選擇基于模數混合電路的SRAM存內計算(Mixed-Mode SRAM based CIM,簡(jiǎn)稱(chēng)MMSCIM)的技術(shù)路徑,具有以下幾點(diǎn)顯著(zhù)的優(yōu)勢:
第一,比純數字實(shí)現的能效比更高,并幾乎等同于純模擬實(shí)現的能效比;
第二,無(wú)需ADC/DAC, 數字實(shí)現的精度,高可靠性和量產(chǎn)一致性,這是數字化天生的優(yōu)勢;
第三,易于工藝升級和不同FAB間的設計轉換;
第四,容易提升速度,進(jìn)行性能/功耗/面積(PPA)的優(yōu)化;
第五,自適應稀疏矩陣,進(jìn)一步節省功耗,提升能效比。
而對于高質(zhì)量的音頻處理和語(yǔ)音應用,MMSCIM是最佳的未來(lái)低功耗端側AI音頻技術(shù)架構。由于減少了在內存和存儲之間數據傳輸的需求,它可以大幅降低延遲,顯著(zhù)提升性能,有效減少功耗和熱量產(chǎn)生。對于要在追求極致能效比電池供電IoT設備上賦能AI,在每毫瓦下打造盡可能多的 AI 算力,炬芯科技采用的MMSCIM技術(shù)是真正實(shí)現端側AI落地的最佳解決方案。
周正宇博士首次公布了炬芯科技MMSCIM路線(xiàn)規劃,從路線(xiàn)圖中顯示:
1、炬芯第一代(GEN1)MMSCIM已經(jīng)在2024年落地, GEN1 MMSCIM采用22 納米制程,每一個(gè)核可以提供100 GOPS的算力,能效比高達6.4 TOPS/W @INT8;
2、到 2025 年,炬芯科技將推出第二代(GEN2)MMSCIM,GEN2 MMSCIM采用22 納米制程,性能將相較第一代提高三倍,每個(gè)核提供300GOPS算力,直接支持Transformer模型,能效比也提高到7.8TOPS/W @INT8;
3、到 2026 年,推出新制程12 納米的第三代(GEN3)MMSCIM,GEN3 MMSCIM每個(gè)核達到1 TOPS的高算力,支持Transformer,能效比進(jìn)一步提升至15.6TOPS/W @INT8。
以上每一代MMSCIM技術(shù)均可以通過(guò)多核疊加的方式來(lái)提升總算力,比如MMSCIM GEN2單核是300 GOPS算力,可以通過(guò)四個(gè)核組合來(lái)達到高于1TOPS的算力。
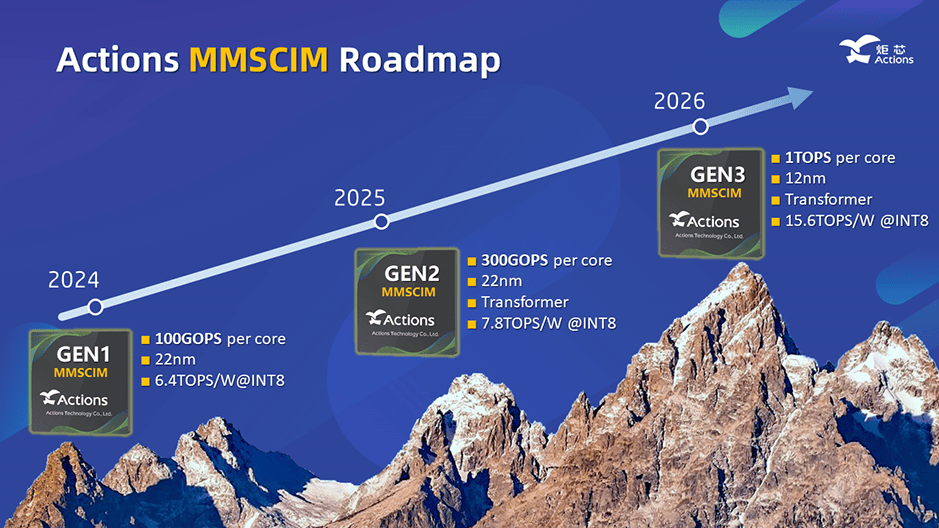
炬芯科技成功落地了第一代MMSCIM在500MHz時(shí)實(shí)現了0.1TOPS的算力,并且達成了6.4TOPS/W的能效比,受益于其對于稀疏矩陣的自適應性,如果有合理稀疏性的模型(即一定比例參數為零時(shí)),能效比將進(jìn)一步得到提升,依稀疏性的程度能效比可達成甚至超過(guò)10TOPS/W?;诖撕诵募夹g(shù)的創(chuàng )新,炬芯科技打造出了下一代低功耗大算力、高能效比的端側AI音頻芯片平臺。
周正宇代表炬芯科技正式發(fā)布全新一代基于MMSCIM端側AI音頻芯片,共三個(gè)芯片系列:
1、第一個(gè)系列是 ATS323X,面向低延遲私有無(wú)線(xiàn)音頻領(lǐng)域;
2、第二個(gè)系列是ATS286X,面向藍牙AI音頻領(lǐng)域;
3、第三個(gè)系列是 ATS362X,面向AI DSP領(lǐng)域。
三個(gè)系列芯片均采用了CPU(ARM)+ DSP(HiFi5)+ NPU(MMSCIM)三核異構的設計架構,炬芯的研發(fā)人員將MMSCIM和先進(jìn)的HiFi5 DSP融合設計形成了炬芯科技“Actions Intelligence NPU(AI-NPU)”架構,并通過(guò)協(xié)同計算,形成一個(gè)既高彈性又高能效比的NPU架構。在這種AI-NPU架構中MMSCIM支持基礎性通用AI算子,提供低功耗大算力。同時(shí),由于A(yíng)I新模型新算子的不斷涌現,MMSCIM沒(méi)覆蓋的新興特殊算子則由HiFi5 DSP來(lái)予以補充。
以上全部系列的端側AI芯片,均可支持片上1百萬(wàn)參數以?xún)鹊腁I模型,且可以通過(guò)片外PSRAM擴展到支持最大8百萬(wàn)參數的AI模型,同時(shí)炬芯科技為AI-NPU打造了專(zhuān)用AI開(kāi)發(fā)工具“ANDT”,該工具支持業(yè)內標準的AI開(kāi)發(fā)流程如Tensorflow,HDF5,Pytorch和Onnx。同時(shí)它可自動(dòng)將給定AI算法合理拆分給CIM和HiFi5 DSP去執行。 ANDT是打造炬芯低功耗端側音頻AI生態(tài)的重要武器。借助炬芯ANDT工具鏈輕松實(shí)現算法的融合,幫助開(kāi)發(fā)者迅速地完成產(chǎn)品落地。

根據周正宇博士公布的第一代MMSCIM和HiFi5 DSP能效比實(shí)測結果的對比顯示:
當炬芯科技GEN1 MMSCIM與HiFi5 DSP均以500MHz運行同樣717K參數的Convolutional Neural Network(CNN)網(wǎng)路模型進(jìn)行環(huán)境降噪時(shí),MMSCIM相較于HiFi5 DSP可降低近98%功耗,能效比提升達44倍。而在測試使用935K 參數的CNN網(wǎng)路模型進(jìn)行語(yǔ)音識別時(shí),MMSCIM相較于HiFi5 DSP可降低93%功耗,能效比提升14倍。
另外,在測試使用更復雜的網(wǎng)路模型進(jìn)行環(huán)境降噪時(shí),運行Deep Recurrent Neural Network模型時(shí),相較于HiFi5 DSP可降低89%功耗;運行Convolutional Recurrent Neural Network模型時(shí),相較于HiFi5 DSP可降低88%功耗;運算Convolutional Deep Recurrent Neural Network模型時(shí),相較于HiFi5 DSP可降低76%功耗。
最后,相同條件下在運算某CNN-Con2D算子模型時(shí),GEN1 MMSCIM的實(shí)測AI算力可比HiFi5 DSP的實(shí)測算力高16.1倍。
綜上所述,炬芯科技此次推出的最新一代基于MMSCIM端側AI音頻芯片,對于產(chǎn)業(yè)的影響深遠,有望成為引領(lǐng)端側AI技術(shù)的新潮流。
從ChatGPT到Sora,文生文、文生圖、文生視頻、圖生文、視頻生文,各種不同的云端大模型不斷刷新人們對AI的預期。然而,AI發(fā)展之路依然漫長(cháng),從云到端將會(huì )是一個(gè)新的發(fā)展趨勢,AI的世界即將開(kāi)啟下半場(chǎng)。
以低延遲、個(gè)性服務(wù)和數據隱私保護等優(yōu)勢,端側AI在IoT設備中扮演著(zhù)越來(lái)越重要的角色,在制造、汽車(chē)、消費品等多個(gè)行業(yè)中展現更多可能性?;赟RAM的模數混合CIM技術(shù)路徑,炬芯科技新產(chǎn)品的發(fā)布踏出了打造低功耗端側 AI 算力的第一步,成功實(shí)現了在產(chǎn)品中整合 AI 加速引擎,推出CPU+ DSP + NPU 三核 AI 異構的端側AI音頻芯片。
最后,周正宇博士衷心希望可以通過(guò)”Actions Intelligence”戰略讓AI真正的隨處可及。未來(lái),炬芯科技將繼續加大端側設備的邊緣算力研發(fā)投入,通過(guò)技術(shù)創(chuàng )新和產(chǎn)品迭代,實(shí)現算力和能效比進(jìn)一步躍遷,提供高能效比、高集成度、高性能和高安全性的端側 AIoT 芯片產(chǎn)品,推動(dòng) AI 技術(shù)在端側設備上的融合應用,助力端側AI生態(tài)健康、快速發(fā)展。





評論